
在 AI 大模型领域,有两项技术最近备受关注:一个是谷歌刚刚发布的 TurboQuant,另一个是微软力推的 BitNet。
那它们之间究竟有何区别?又有什么关系呢?
简单来说,TurboQuant 是一位精于“整理房间”的收纳大师,能让你现有的房间放下更多东西;而 BitNet 则是一位“建筑师”,从一开始就设计了一座空间利用率极高的房子。
前者专注于解决大模型在推理时的内存瓶颈,让现有模型跑得更快、更省内存;后者则从头构建了一种全新的、极度轻量化的模型架构,让大模型甚至可以在 CPU 上流畅运行。
下面,我们来深入聊聊它们到底是什么,以及各自有什么绝活。
🚀 核心差异:一张表看懂
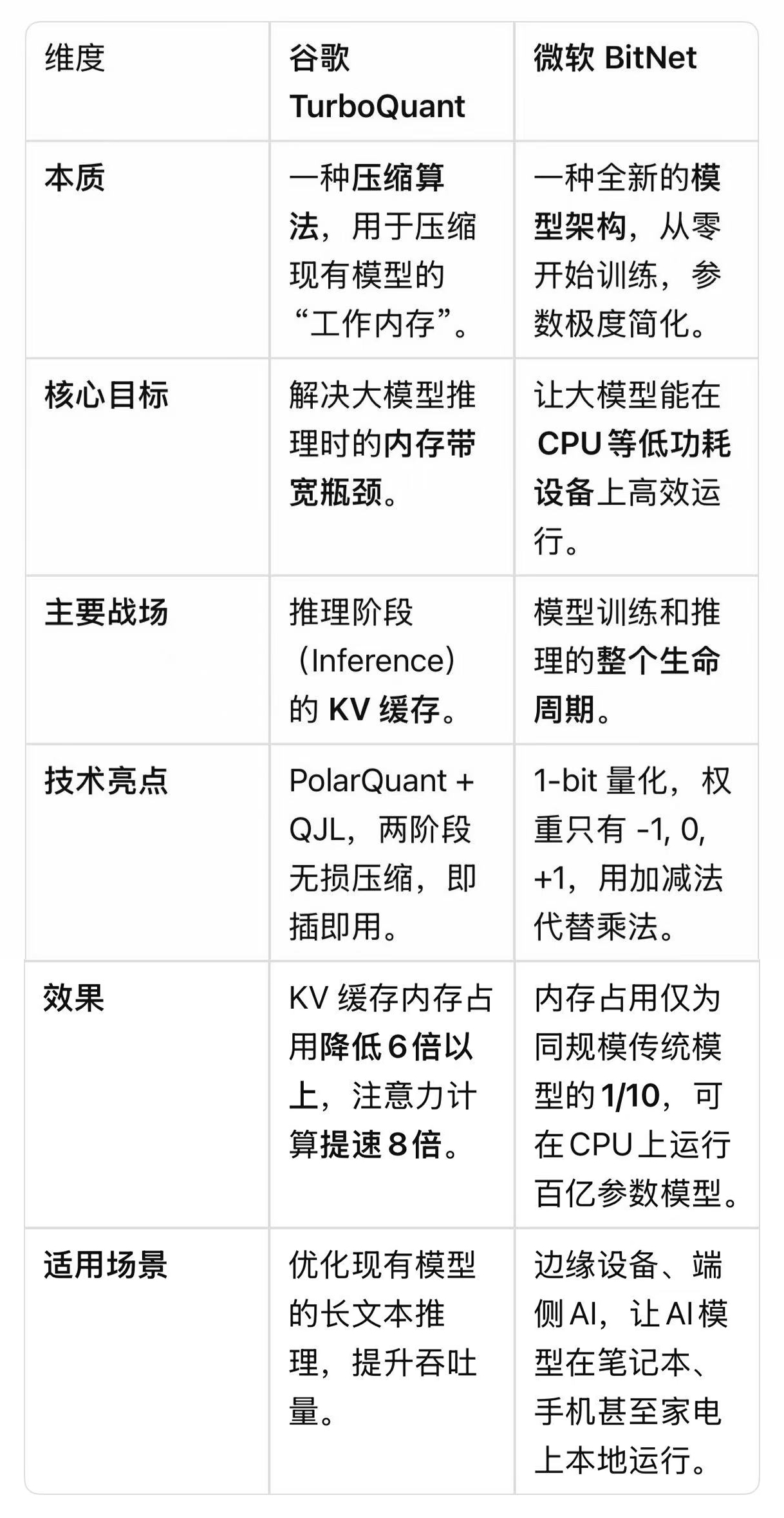
🧠 谷歌 TurboQuant:给大模型“减负”的极致压缩
它是来解决什么问题的?
想象一下,大模型在和你对话时,手里一直握着一本不断变厚的“记事本”,用来记录之前的对话内容,以免重复计算。这个“记事本”就是 KV 缓存(Key-Value Cache)。当处理超长文档或复杂对话时,这个“记事本”会迅速膨胀,占满昂贵的高性能内存,导致 AI 回答变慢甚至崩溃。传统的内存量化方法,要么压缩效果有限,要么会因为额外存储参数而“偷走”节省下来的空间,得不偿失。
TurboQuant 是怎么做到的?
TurboQuant 的厉害之处在于,它采用了一套两阶段、近乎无损的压缩方案,完全不需要重新训练模型,拿过来就能用。
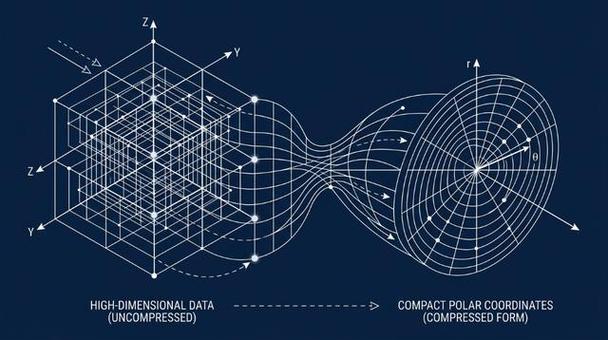
第一阶段:PolarQuant —— 换一套坐标系,消灭“元数据”
传统的量化方法,是在我们熟悉的直角坐标系里干活,每个数据点都需要单独标注位置,导致巨大的“元数据”开销。TurboQuant 的 PolarQuant 做了一个聪明的转变:它先对数据向量进行随机旋转,然后改用极坐标(角度和半径)来表示。在高维空间里,经过这种变换后,所有向量的角度部分会神奇地收敛到一个固定分布。这意味着,系统可以用一套全局的“刻度尺”来量化所有向量,不再需要为每个数据块单独存储校准参数,彻底消灭了元数据开销。这一步完成了绝大部分的高质量压缩。
第二阶段:QJL —— 用1比特信息,无偏差地修正误差
PolarQuant 压缩后,还会残留微小的误差。如果放任不管,这些误差会累积起来,让 AI 的注意力变得不准确,最终导致“幻觉”或回答偏离主题。TurboQuant 的第二步就是用一个名为 QJL(Quantized Johnson-Lindenstrauss) 的方法来处理这些残差。它只用了1个比特(一个正负号)来表征残差,然后通过巧妙的数学变换,保证了压缩后的向量和原始向量在做点积运算时,其统计期望是完全一致的。这意味着误差被无偏差地修正了,从根本上杜绝了精度损失。
效果如何?
- 极致压缩:将KV缓存压缩到每通道仅3比特,内存占用至少减少6倍。
- 速度飞跃:在 H100 GPU 上,注意力计算环节的速度最高可提升8倍。
- 零精度损失:在“大海捞针”等严苛的长上下文测试中,召回率依然能达到100%。
简单来说,TurboQuant 就像是给你的 AI 服务器来了一次“内存扩容”,让同样的硬件能处理更长的文本或支持更多用户,大大降低了推理成本。
🧮 微软 BitNet:重铸模型架构,让 CPU 也能跑大模型
它是来解决什么问题的?
传统的 AI 模型(如 GPT 系列)依赖高精度的浮点数(如 FP16)进行计算,这需要强大的 GPU 和大量显存。微软的 BitNet 试图从根源上改变这一点,它的目标是让大模型不再“非 GPU 不可”,甚至能在你手头的笔记本 CPU 上飞速运行。
BitNet 是怎么做到的?
BitNet 的核心思想是 1-bit 量化,它从训练阶段就采用了全新的架构。
极致精简的权重值
传统模型使用复杂的 16 位或 32 位浮点数来表示权重。而 BitNet b1.58 将模型中的每一个权重都限制在三个数值:-1, 0, +1。在信息论上,这相当于用约 1.58 个比特来存储一个参数。这让模型的体积变得极小,一个 20 亿参数的 BitNet 模型,大小仅为 0.4GB。
用加减法代替乘法
这是 BitNet 革命性的地方。因为权重值只有 -1, 0, 1,所以原来最耗费算力的浮点乘加运算(MAC),就可以被简单的整数加法所取代。这使得模型在缺乏专用张量核心的 CPU 上运行时,也能获得巨大的速度提升。
专为 CPU 设计的推理框架
为了充分发挥其优势,微软还开发了专门的推理框架 bitnet.cpp。该框架专为 ARM 和 x86 架构的 CPU 进行了优化,测试表明,在苹果的 M 系列芯片上运行 BitNet 模型,速度是传统 FP16 模型的 1.37 倍到 5 倍,同时能耗降低了 55% 到 70%。

效果如何?
- 性能强大:研究证明,当模型规模达到 1000 亿参数时,BitNet 的性能可以媲美同规模的传统 FP16 模型。
- 颠覆性能效:能效比提升了 70 倍以上,意味着更省电、更环保。
- 本地部署:让在个人电脑、智能手机甚至智能家电上运行强大、且保护隐私的本地 AI 成为可能。
BitNet 的意义在于,它证明了我们不需要追求极致的算力,也能拥有强大的 AI。它为 AI 从云端下沉到各类边缘设备,铺平了道路。
💎 总结
无论是谷歌的 TurboQuant,还是微软的 BitNet,它们都代表了 AI 基础设施朝着 “高效”与“普惠” 方向的深刻变革。
- TurboQuant 是一项出色的软件优化技术,它让现有模型在高端硬件上发挥出更大的潜力,直接降低了运营成本。
- BitNet 则是一种更底层的硬件友好型架构,它让 AI 模型有机会摆脱对昂贵 GPU 的依赖,走向千行百业的终端设备。
两者并非竞争关系,更像是推动 AI 落地的“两条腿”。
未来,我们很可能会看到这两种技术的结合:一个用 BitNet 架构训练的模型,再用 TurboQuant 技术进行推理加速,共同打造出既轻量又高效的 AI 应用。
